
임베딩 아틀라스: 저저항, 대화형 임베딩 시각화
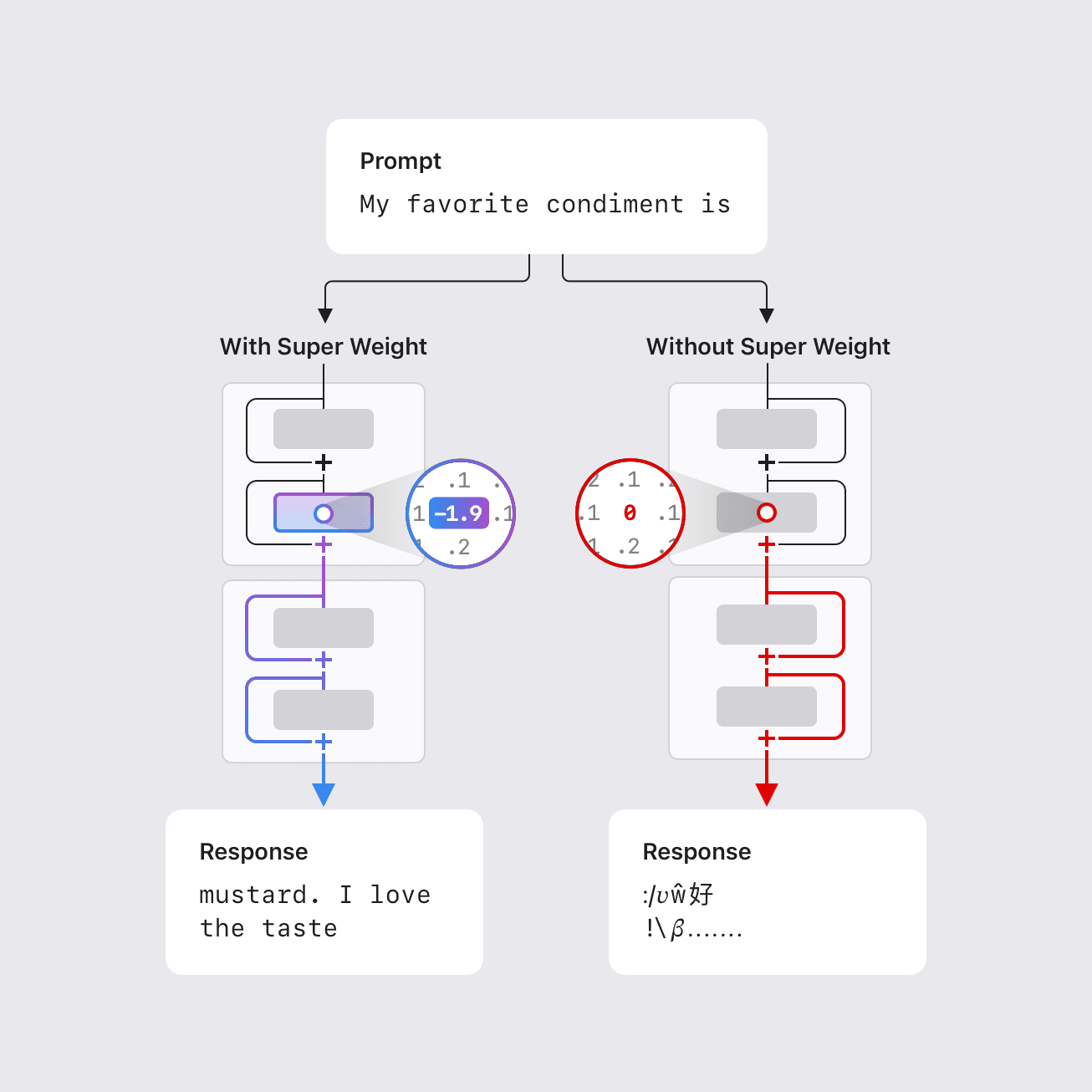
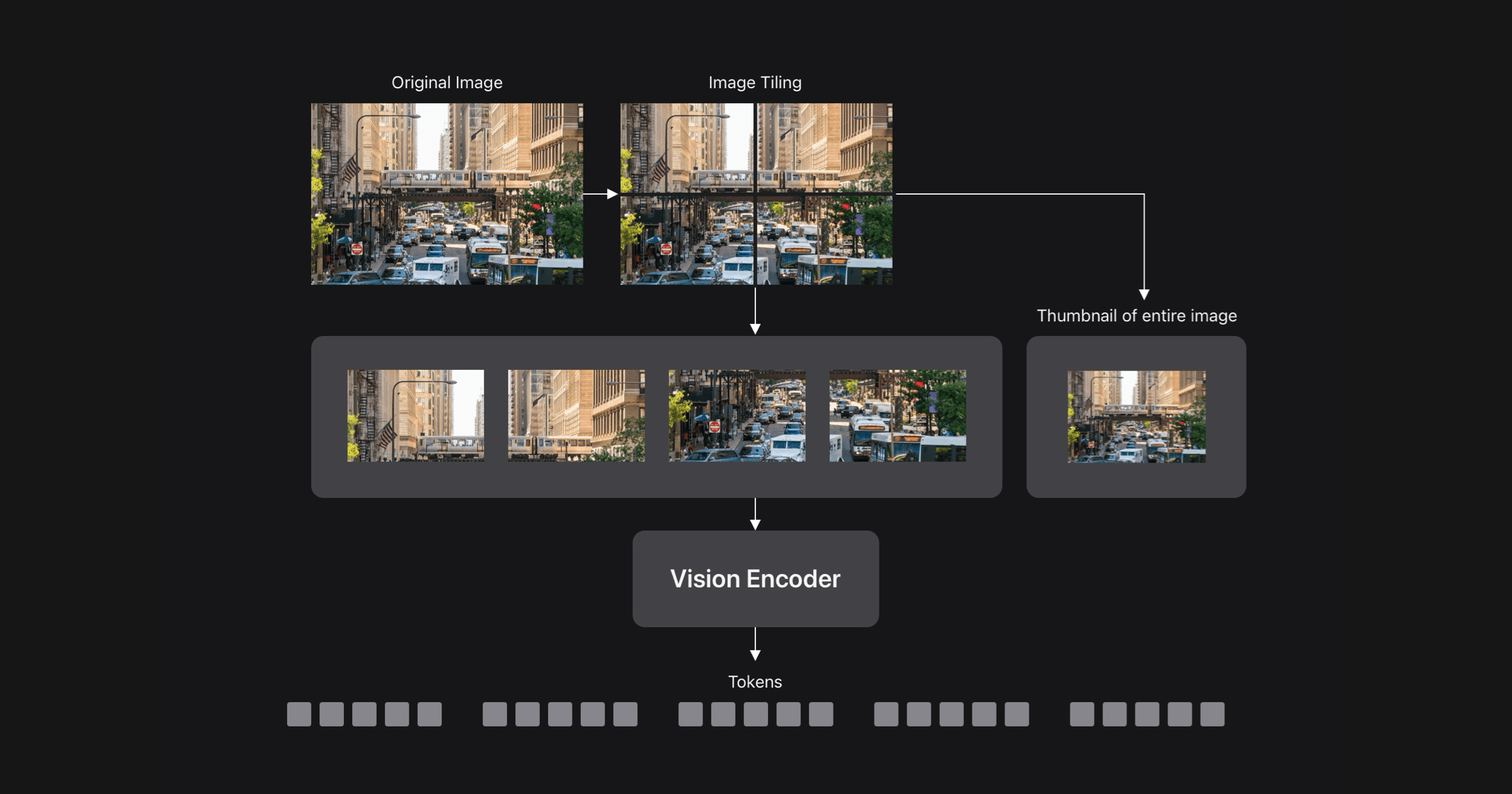
Embedding Atlas는 대규모 데이터셋 및 모델을 시각화하는 데 널리 사용되는 임베딩 프로젝션이지만, 사용자들은 종종 임베딩 시각화 도구를 사용할 때 “저항”을 겪는다. 이 논문에서는 대규모 임베딩과 상호 작용하는 데 쉽게 접근할 수 있도록 설계된 확장 가능한 대화형 시각화 도구인 Embedding Atlas를 제시한다.