




인공지능 에이전트의 인터넷? Coral 프로토콜이 MCP 네이티브 런타임 및 레지스트리인 Coral v1을 소개합니다
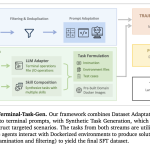
Coral Protocol은 Coral v1을 출시하여 개발자가 이질적인 프레임워크 간에 AI 에이전트를 발견, 구성 및 운영하는 방식을 표준화하고 있습니다. 이 릴리스는 스레드, 언급 주소 지정된 에이전트 간 메시징이 가능한 MCP 기반 런타임(Coral Server), 오케스트레이션 및 가시성을 위한 개발자 워크플로우(CLI + Studio), 그리고 에이전트용 공개 레지스트리에 중점을 두고 있습니다.
2025년 9월 20일 오후 7시 24분