




Nous 연구팀, 하이브리드 추론을 사용한 Hermes 4 공개
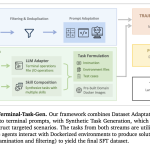
Nous 연구팀이 Hermes 4를 발표했다. 이 모델은 순수 사후 훈련 기술을 통해 선두 수준의 성능을 달성하는데, 복잡한 문제에 대한 심층 고찰이 필요할 때 모델이 표준 응답과 명시적 추론 사이를 전환할 수 있는 하이브리드 추론을 소개했다.
2025년 8월 28일 오전 1시 03분