
Apple, 코드 생성용 7B Diffusion LLM인 DiffuCoder 소개
Apple이 코드 생성을 위해 맞춤화된 7B Diffusion LLM인 DiffuCoder를 소개했다. LLMs는 대화부터 코드 생성까지 다양한 작업에서 놀라운 결과를 얻어내며 자연어 처리를 혁신시켰다.
2025년 7월 16일 오후 7시 02분



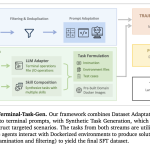


Apple이 코드 생성을 위해 맞춤화된 7B Diffusion LLM인 DiffuCoder를 소개했다. LLMs는 대화부터 코드 생성까지 다양한 작업에서 놀라운 결과를 얻어내며 자연어 처리를 혁신시켰다.

NVIDIA의 Audio Flamingo 3 (AF3)은 기계가 소리를 이해하고 추론하는 방식에 큰 발전을 이끌어냈다. 이전 모델들은 음성을 전사하거나 오디오 클립을 분류할 수는 있었지만, AF3는 음성, 주변 소리 등을 인간과 유사한 맥락에서 해석하는 능력을 갖췄다.

본 튜토리얼에서는 CrewAI와 Google의 Gemini 모델을 사용하여 최적화된 다중 AI 에이전트 시스템을 구축하는 방법을 안내합니다. 연구, 데이터 분석, 콘텐츠 생성, 품질 보증을 위한 특화된 에이전트들을 순차적 협업에 최적화된 상태로 설치하고 구성합니다.

다양한 데이터 유형이 혼합된 콘텐츠를 처리하는 더 지능적이고 유용한 AI 시스템 구축이 중요해지고 있다. 이 논문은 텍스트와 구조화된 테이블을 동시에 다루는 질문에 초점을 맞춘 프레임워크 TableRAG를 소개한다.

음성 개선 기술이 전통적인 마스크 또는 신호 예측 방법을 넘어서 사전 훈련된 오디오 모델을 활용하여 성능을 향상시키고 있습니다. 이러한 모델은 의미 있는 오디오 임베딩을 추출하여 음성 개선의 성능을 향상시킵니다.

아마존이 새롭고 혁신적인 AI 통합 개발 환경 ‘Kiro’를 발표했다. 오늘의 AI 코딩 어시스턴트의 능력을 훨씬 뛰어넘는 Kiro는 명세 주도 개발, 지능적 자동화, 적응형 사용자 인터페이스에 혁신을 제공한다.

MetaStone-S1은 새로운 반사 생성 형태를 통해 OpenAI o3-mini의 성능을 달성하는 반사 생성 모델로, 기존의 LLMs와는 다른 Test-Time Scaling (TTS) 방식을 사용하여 추론 성능을 향상시킵니다.

구글의 Gemini Embedding 텍스트 모델 gemini-embedding-001이 Gemini API와 Google AI Studio를 통해 개발자들에게 일반적으로 제공되었으며, 강력한 다국어 및 유연한 텍스트 표현 기능을 AI 생태계로 확대시켰다. 다국어 지원, 차원적 유연성 기술 명세 및 모델 성능 주요 기능 메트릭/작업 Gemini-embedding-001 레거시 구글 모델 Cohere v3.0 OpenAI-3-large MTEB (다국어) 평균 […]

MLflow는 머신러닝 실험을 관리하고 추적하는 오픈소스 플랫폼이다. OpenAI Agents SDK와 함께 사용할 때 MLflow는 에이전트 응답 추적을 자동화한다. 에이전트 간의 협력이나 동적 함수 호출이 필요한 다중 에이전트 시스템을 구축할 때 유용하다.

이 기사에는 LLMs에서의 현재 테스트 시간 계산 전략의 한계, 훈련 무료 및 모델에 중립적인 프레임워크로서의 분수적 추론(FR)의 소개, 추론 프롬프트 및 조정 가능한 스케일링을 사용한 잠재 상태 조작 기술, GSM8K, MATH500 및 GPQA에서의 너비 및 깊이 기반 스케일링 이점 등이 포함되어 있습니다. FR의 우수성을 보여주는 평가 결과 및 분석이 제시됩니다.

Liquid AI가 새로운 엣지 LLMs인 LFM2를 오픈소스로 공개했다. 이 모델은 2배 빠른 추론과 3배 빠른 학습 성능을 제공하며, 컨볼루션과 어텐션 블록을 혼합한 하이브리드 설계를 특징으로 한다. 350M, 700M, 1.2B 파라미터 크기의 세 가지 모델이 제공되며, 유사한 크기의 모델과 비교했을 때 우수한 성능을 보여준다.

전문 의료 추론을 보다 접근하기 쉽게 만들어주는 AI의 잠재력이 있지만 현재의 평가는 간단화된 정적 시나리오에 의존하여 부족하다. 진짜 임상 실무는 훨씬 동적하며, 의사들은 진단 접근법을 단계별로 조정하며 목표로 하는 질문을 하고 새로운 정보를 해석한다. 이 반복적 과정은 그들이 가설을 정제하는 데 도움이 된다.

대규모 멀티모달 모델(LMMs)은 이미지 해석, 시각적 질문에 답변, 다중 모달을 결합하여 사실 정보를 검색하는 시스템을 가능하게 한다. 그러나 대량의 학습 데이터가 있더라도 LMMs는 종종 동적이거나 발전하는 정보를 간과하는데, 특히 학습 후에 나타나는 사실들을 놓칠 수 있다.

구글 딥마인드가 최근 발표한 GenAI 프로세서는 가벼운 오픈소스 파이썬 라이브러리로, 실시간 다중 모달 콘텐츠를 포함한 생성 AI 워크플로우의 조율을 간소화하는 데 사용된다. 이 라이브러리는 고급 AI 파이프라인을 구축하기 위한 고청량, 비동기 스트림 프레임워크를 제공한다.

밀도 기능 이론(DFT)은 현대 계산 화학과 재료 과학의 기초 역할을 합니다. 그러나 높은 계산 비용으로 인해 사용이 제한됩니다. 기계 학습 상호 원자력(MLIP)은 DFT 정확도를 근접하게 흉내내며 계산 시간을 현저히 단축시키는 잠재력이 있습니다.

2025년 7월 Moonshot AI가 발표한 Kimi K2는 1조개의 총 매개변수와 토큰당 32억개의 활성 매개변수를 갖춘 MoE 모델로, 1550억 토큰에 대해 훈련되었다. K2는 대규모 모델에서 흔히 볼 수 있는 불안정성 없이 전례 없는 규모에서 안정적인 훈련을 달성했다.

신체화된 AI 에이전트는 물리적 또는 가상 형태로 존재하며 주변 환경과 상호 작용할 수 있는 시스템이다. 이들은 세계를 지각하고 의미 있는 행동을 취한다. 최근의 발전은 신체화가 된 AI 에이전트의 물리적 상호작용, 인간 신뢰, 인간과 유사한 학습을 향상시킨다.

인간 시각 지각과 몸의 움직임 간의 연결을 이해하는 것은 지능형 시스템을 개발하는 데 중요하다. PEVA는 인간의 몸 운동을 기반으로 에고센트릭 시점에서 보이는 것을 예측하는 모델이다.

Mistral AI가 All Hands AI와 협력하여 Devstral 2507 레이블 하에 개발자 중심 대형 언어 모델의 업데이트 버전을 출시했다. Devstral Small 1.1과 Devstral Medium 2507 두 모델은 대규모 소프트웨어 저장소에서 에이전트 기반 코드 추론, 프로그램 합성, 구조화된 작업 실행을 지원하기 위해 설계되었으며 성능에 최적화되어 있다.

AI 에이전트를 시장에 내놓기 위해 개발자들이 노력하고 있지만, 지난 상호작용을 회상할 수 있는 능력의 부족이 큰 장애물이었습니다. 이로 인해 대화마다 처음으로 대하는 것처럼 취급되어 반복적인 질문, 사용자 선호도 기억 불가능, 일반적인 맞춤화 부재로 이어졌습니다.

Microsoft의 Phi-4 모델 패밀리에 최신 추가인 Phi-4-mini-Flash-Reasoning은 장기 문맥 추론에 뛰어나면서 높은 추론 효율성을 유지하는 경량 언어 모델이다. 3.8B 파라미터 모델은 밀도 높은 추론 작업(수학 문제 해결, 다중 점프 질문 응답)에 적합하도록 Fine-tuned 되었다.

AI 기반 비디오 생성 기술이 빠르게 발전하고 있으며, NVIDIA의 DiffusionRenderer는 단일 비디오에서 편집 가능하고 사실적인 3D 장면을 생성하는 AI 모델을 소개했다. 이 모델은 놀라운 현실감을 가진 비디오를 생성하는 능력을 갖추고 있다. 그러나 이제는 전문적이고 현실적인 편집 기능이 추가되어 사용자가 비디오를 보다 전문적으로 수정할 수 있다.

이 튜토리얼에서는 병렬 컴퓨팅을 활용하여 데이터 워크플로우를 크게 가속화하는 강력한 Pandas 대체 도구인 Modin에 대해 알아본다. modin.pandas as pd로 가져와 Pandas 코드를 분산 처리 강자로 변환한다. Modin이 실제 데이터 작업에서 어떻게 수행되는지 이해하는 것이 목표다.

구글 DeepMind와 구글 연구가 MedGemma 우산 아래 두 가지 새로운 모델을 소개했습니다. MedGemma 27B는 대규모 비전-언어 기반 모델이며 MedSigLIP는 가벼운 의학 이미지-텍스트 인코더입니다. 이들은 건강 인공지능 분야에서 가장 능력있는 오픈 소스 모델입니다.

Perplexity사가 AI 기반 검색을 통해 정보 상호작용을 재정의했는데, 이번에는 AI 네이티브 웹 브라우저인 Comet을 출시했다. Comet은 AI-First 아키텍처로 설계되어 사용자가 웹 콘텐츠를 탐색하고 상호작용하는 방식을 혁신적으로 변화시킬 예정이다.

Salesforce AI가 새로운 GUI 에이전트인 GTA1을 소개했다. GTA1은 리눅스와 같은 OS 환경에서 자율적으로 작동하며, 모호한 작업 계획과 부정확한 행동 기반에 대한 두 가지 핵심 병목 현상을 해결한다. 45.2%의 작업 성공률을 보이며 OpenAI의 CUA를 능가한다.

AI 주도적 세계에서 프롬프트 엔지니어링은 중요한 기술이다. 이는 간단한 질의를 넘어서 모호한 아이디어를 명확하고 실행 가능한 AI 결과물로 변환할 수 있는 능력을 제공한다. ChatGPT 4o, Google Gemini 2.5 플래시, Claude Sonnet 4 등을 사용하는 경우 네 가지 기본 원칙이 전체 잠재력을 발휘하게 한다.

Microsoft이 AI 기반 코딩 어시스턴트인 GitHub Copilot 채팅 익스텐션을 모든 개발자에게 무료로 공개했다. 이전에는 구독이 필요했던 기능이 이제 MIT 라이선스로 공개되어 누구나 사용 가능하다.

Hugging Face가 SmolLM3을 공개했다. 3B 파라미터 아키텍처를 사용하여 강력한 다국어 추론을 제공하며 상태-of-the-art 성능을 획득하였다. 더 적은 파라미터로 비용 효율적이고 제약된 환경에서도 배포 가능하다.

BeeAI 프레임워크를 사용하여 다중 에이전트 시스템을 구축하는 방법을 탐구하는 튜토리얼. BeeAI가 지능적이고 협력적인 에이전트의 개발을 어떻게 간단하게 만드는지 보여줌.

Anthropic이 선도적 AI 모델을 대상으로 한 투명성 프레임워크를 소개하며, 안전, 감독, 위험 관리에 대한 우려가 증가하고 있는 상황을 다루고 있다. 이 프레임워크는 가장 높은 잠재적 영향과 위험을 가진 선도적 AI 모델을 대상으로 하며, 작은 개발자 및 스타트업은 의도적으로 제외되어 넓은 AI 혁신을 억제하지 않고 있다.

구글은 MCP 툴박스를 발표했는데, 이는 GenAI Toolbox의 일환으로 SQL 데이터베이스를 AI 에이전트에 통합하는 것을 간소화하는 데 목적을 둔 오픈 소스 모듈이다. 이 릴리스는 언어 모델이 외부 시스템과 상호 작용할 수 있게 하는 표준화된 접근 방식인 모델 컨텍스트 프로토콜(MCP)을 발전시키기 위한 구글의 전략의 일환이다.

본 튜토리얼에서는 PrimisAI Nexus 프레임워크를 활용하여 OpenAI API와 통합된 다중 에이전트 작업 자동화 시스템을 구축하는 방법을 소개합니다. 계층적 감독, 지능적인 도구 활용 및 구조화된 출력을 통해 여러 AI 에이전트의 협조를 통해 복잡한 작업을 수행하는 방법을 보여줍니다.

비디오 확산 모델과 계산적 도전에 대한 소개. 이미지 합성의 성공을 바탕으로 확산 모델이 뛰어난 질과 일관성 있는 비디오를 생성하는 데 큰 진전을 이루었지만, 비디오의 추가적인 시간적 차원 처리는 계산 요구를 크게 증가시킴. 이로 인해 자기 주의는 시퀀스 길이에 따라 늘어나는데, 이는 이러한 모델을 훈련하거나 실행하는 것을 어렵게 만듦.

Osmosis AI가 고도로 정확하고 구조화된 코드 병합 작업을 수행하기 위해 설계된 Osmosis-Apply-1.7B를 오픈소스로 공개했다. 이 모델은 IDE 에이전트에서 영감을 받아 문맥에 민감하고 함수 수준의 코드 편집에 최적화되어 있으며, 코드 특정 포맷팅을 활용하여 더 적은 파라미터로 강력한 성능을 달성한다.

바이트댄스가 대형 언어 모델(LLM)을 활용한 일반 목적 소프트웨어 엔지니어링 에이전트 ‘Trae Agent’를 공식 출시했다. 복잡한 프로그래밍 작업을 자연어 프롬프트를 통해 실행할 수 있는 Trae Agent는 뛰어난 성능과 확장성을 제공하는 명령줄 인터페이스(CLI)를 제공하여 개발자들이 소프트웨어와 상호 작용하는 방식을 새롭게 정의한다.

ACP는 AI 에이전트, 애플리케이션, 인간 간 원활한 통신을 위한 오픈 표준이다. 다양한 프레임워크 및 인프라를 사용하여 개발된 AI 시스템은 종종 격리되어 호환되지 않을 수 있는데, ACP는 이러한 단절을 해소하고 통일된 RESTful API를 제공하여 협업 능력을 확장한다.

현재의 보상 모델의 한계를 이해하는 것은 중요하다. 오늘날의 최고의 모델들도 여전히 복잡한 인간 선호도의 전체 범위를 반영하는 데 어려움을 겪고 있다. 훈련 기술이 발전해도 의미 있는 진전이 제한되어있는데, 주요 이유는 모델의 한계 때문이다.

대형 언어 모델은 인간 사용을 최적화하기 위해 추가 정렬 단계가 필요한데, 강화 학습을 통해 모델이 인간 피드백이나 작업 기반 정확성에 따라 결정을 내릴 수 있게 함. 이를 통해 모델이 더 밀접하게 정렬될 수 있음.

컨텍스트 엔지니어링은 대형 언어 모델(LLM)에 공급되는 컨텍스트를 설계, 조직화 및 조작하는 학문을 의미하며 모델 가중치나 아키텍처를 미세 조정하는 대신 입력에 초점을 맞춥니다. 이 기술은 프롬프트, 시스템 지침, 검색된 지식, 포맷팅 및 심지어 순서 등을 최적화하여 LLM의 성능을 향상시킵니다.

DSPy 프레임워크를 활용하여 지능적이고 자가 수정 가능한 질문-답변 시스템을 구축하는 방법에 대해 탐구합니다. 구조화된 서명을 정의하여 zu의 동작을 명확히하는 것으로 시작하여 DSPy의 선언적 프로그래밍 접근 방식을 통해 신뢰할 수 있는 파이프라인을 구축합니다.

Chai Discovery Team이 Chai-2를 소개했다. 이는 제로샷 De Novo 항체 디자인을 가능케 하는 멀티모달 AI 모델로, 각각의 대상에 대해 최대 20명의 후보자를 사용하여 52가지의 신규 대상에서 16%의 성공률을 달성했다. Chai-2는 이전 방법보다 100배 이상 우수한 결과를 보여주며, 2주 미만의 시간 내에 유효한 결합체를 제공하여 대규모 스크리닝의 필요성을 없앴다.

작은 LLM은 강건한 추론에 어려움을 겪는데, 익숙한 문제에서는 잘 작동하지만 이름이나 숫자를 바꾸거나 관련 없는 정보를 추가하는 등 약간의 변경으로 성능이 급격히 감소하는 것이 보고되고 있다.

Kyutai가 2조 개의 파라미터로 구성된 혁신적인 스트리밍 텍스트 음성 변환 모델을 발표했습니다. 이 모델은 초저지연 시간(220밀리초)으로 고품질의 오디오 생성을 제공하며 전례없는 2.5백만 시간의 오디오로 훈련되었습니다. CC-BY-4.0에 따라 라이선스가 부여되었습니다.

Meta AI와 Washington 대학의 연구진이 ASTRO(자동 회귀 검색 가르치는 추론기)를 소개했다. Llama-3.1-70B-Instruct에서 추론을 향상시키기 위한 포스트 트레이닝 프레임워크로, 모델에 컨텍스트 내 검색 수행을 가르치는 것이 특징이다.

오픈AI Codex는 소프트웨어 엔지니어링에서 루틴한 부분을 처리하여 고수준 사고에 집중할 수 있도록 돕는다. 이 튜토리얼에서는 Codex와 GitHub 저장소를 연동하는 방법에 대해 안내한다.

보상 모델은 LLM과 인간 피드백을 일치시키는 데 필수적이지만, 보상 해킹 문제에 직면한다. 이 모델들은 응답 길이나 형식과 같은 표면적 특성에 초점을 맞추고 사실성 및 관련성과 같은 진정한 품질 지표를 식별하지 못한다. 이 문제는 표준 훈련 목표가 의미 없는 상관 관계를 구별하지 못하기 때문에 발생한다.

대규모 언어 모델의 핵심 추론 단계를 식별하고 측정하는 머신러닝 프레임워크인 Thought Anchors 소개. 현재 해석 도구의 한계를 이해하는데 중점을 두며, DeepSeek 및 GPT 변형과 같은 AI 모델이 복잡한 추론 작업을 처리하는 데 어려움을 겪고 있음을 설명.

TNG 기술 컨설팅이 새로운 AoE 모델인 DeepSeek-TNG R1T2 Chimera를 발표했다. R1-0528, R1, V3-0324 세 부모 모델로 구성된 R1T2는 전문가 계층 보간을 통해 대형 언어 모델에서 새로운 효율성을 발휘한다.

BioCypher AI 에이전트를 구현하여 생명 과학 지식 그래프를 구축, 쿼리 및 분석하는 튜토리얼. BioCypher의 강점과 NetworkX의 유연성을 결합하여 복잡한 생물 관계를 시뮬레이션할 수 있도록 사용자에게 권한을 부여.

Together AI가 최신 기술인 강화학습을 통해 완전히 오픈소스로 훈련된 소프트웨어 공학 에이전트인 DeepSWE를 출시했다. Qwen3-32B 언어 모델을 기반으로 한 DeepSWE는 SWEBench-Verified 벤치마크에서 59% 정확도와 42.2% Pass@1을 달성하여 오픈 웨이트 모델 중 최고의 성과를 거뒀다.

연구원들이 OctoThinker를 제안하여 강화 학습을 통한 복잡한 추론 작업에 대한 LLM의 발전을 제안했다. CoT 프롬프팅과 대규모 강화 학습을 결합한 LLM은 Deepseek-R1-Zero와 같은 모델이 기본 모델에 직접 RL을 적용함으로써 강한 추론 능력을 보여주었다.

대형 언어 모델은 논리적 사고 과정을 시뮬레이션하는 중간 단계를 통해 추론 정확도를 향상시키고 오류를 명확히 합니다. ReasonFlux-PRM은 LLM에서 이러한 사고 연쇄를 향상시키는 궤적 인식 보상 모델입니다.

최신 검색 시스템은 사용자 쿼리의 부피와 복잡성이 증가함에 따라 콘텍스트 인식 및 적응형 정보 검색 수요가 높아지고 있습니다. 이에 바이두 연구원들은 단순 키워드 일치나 문서 순위 매기기에 그치던 시스템을 넘어 계층적 추론이 필요한 사용자 쿼리에 대응하는 지능적이고 적응형 검색 엔진을 제안합니다.

바이두가 최신 ERNIE 4.5 시리즈를 오픈 소스로 공개했다. 이는 언어 이해, 추론 및 생성을 강화하기 위해 설계된 강력한 foundation 모델의 가족이다. 공개된 모델은 0.3B 밀집 모델부터 424B 파라미터를 가진 거대한 MoE(Mixture-of-Experts) 아키텍처까지 10가지 모델 변형을 포함하고 있다.

DeepSeek-R1과 같은 대규모 언어 모델이 수학 문제에서 우수한 결과를 보이지만, 일부 모델은 알려진 대수 규칙을 반복하거나 다이어그램 문제에서 좌표 기하학을 사용하는 등 한정된 기법에 의존한다. OMEGA는 이러한 모델의 추론 한계를 탐구하기 위한 구조화된 수학 벤치마크이다.

이 튜토리얼에서는 AutoGen과 Semantic Kernel을 Google의 Gemini Flash 모델과 원활하게 통합하는 방법을 안내합니다. GeminiWrapper 및 SemanticKernelGeminiPlugin 클래스를 설정하여 Gemini의 생성력과 AutoGen의 Multi-Agent Orchestration을 연결하는 과정부터 코드 리뷰어에서 창의적 분석가까지 다양한 전문 에이전트를 구성하는 방법을 보여줍니다.

타블러 기계 학습에서 벤치마킹의 중요성을 이해하고, 정형 데이터에서 패턴을 학습하는 모델을 구축하는 것에 초점을 맞추고 있습니다. 이는 정확성과 해석 가능성이 필수적인 의료 및 금융 분야에서 사용됩니다.

LongWriter-Zero는 강화 학습 기반의 프레임워크로, 수천 단어에 걸쳐 있는 초장문 텍스트 생성에 도전하는 것을 소개하며, 대규모 언어 모델이 직면한 문제점들을 다루고 있다. 주요 문제로는 불일치, 주제 이탈 등이 있다.

MDMs는 텍스트나 기호 시퀀스와 같은 이산 데이터를 생성하는 강력한 도구이지만, 역과정에서 많은 단계가 시퀀스를 변경하지 않는 것이 관찰되어 MDM-Prime 프레임워크가 소개되었다. 이 프레임워크는 샘플링 중 일부 토큰을 언마스크하면서 시퀀스 생성 효율을 향상시킨다.

핸드 코딩된 명령을 대체하는 방법을 통해 로봇 제어 시스템은 데이터 기반 학습을 통해 큰 발전을 이루었습니다. 현대 로봇은 명시적 프로그래밍 대신 행동을 관찰하고 모방함으로써 학습합니다. 이러한 학습 방식은 구조화된 환경에서 로봇이 효과적으로 작동할 수 있게 합니다.

미시간 대학 연구진이 G-ACT를 소개했다. 이는 프로그래밍 언어 편향을 조절하기 위한 확장 가능한 기계 학습 프레임워크로, LLMs의 과학적 코드 생성에 활용될 수 있다.

이 튜토리얼에서는 신호 처리에 의존하지 않고 Lilac 라이브러리를 사용하여 완전히 기능적이고 모듈화된 데이터 분석 파이프라인을 구축하는 방법을 보여줍니다. Lilac의 데이터셋 관리 기능을 Python의 함수형 프로그래밍 패러다임과 결합하여 깔끔하고 확장 가능한 워크플로우를 생성합니다. 프로젝트 설정부터 실제 샘플 데이터 생성, 통찰력 추출 및 필터링된 내보내기까지의 과정을 안내합니다.

UC San Diego 연구진이 로봇학 분야에서 민첩한 손 조작을 위한 10억 규모의 Dex1B 데이터셋을 소개했다. 손 조작을 위한 대규모 데이터 수집은 로봇공학에서 여전히 주요 과제이며, 이번 데이터셋은 민첩한 손의 복잡성을 효과적으로 다룰 수 있는 방법을 모색하고 있다.

Python을 사용하여 LangChain으로 구동되는 AI 에이전트에 통합할 수 있는 강력하고 지능적인 데이터 분석 도구를 만드는 방법을 안내하는 튜토리얼. 사용자 입력을 위한 구조화된 스키마를 정의하고 상관 분석과 같은 주요 기능을 구현함으로써 사용자 정의 AI 에이전트를 구축하는 중요성을 강조.

희귀병은 전 세계 4억 명을 영향을 미치며, 7,000가지 이상의 질병 중 80% 이상이 유전적 원인을 가지고 있다. 이러한 희귀병의 진단은 어려운데, DeepRare는 AI 기술을 활용하여 임상 의사 결정을 개선하고 환자의 진단 과정을 단축시키는 첫 번째 시스템이다.

텐센트의 훈유안 팀이 희소 MoE 아키텍처로 구축한 새로운 오픈소스 대형 언어 모델인 훈유안-A13B를 소개했다. 이 모델은 80억 개의 총 파라미터 중 추론 중에는 13억 개만 활성화되어 성능과 계산 비용 사이에 뛰어난 효율을 제공한다. 그룹화된 쿼리 어텐션 (GQA), 256K 컨텍스트 길이 등을 지원한다.

Gemini CLI는 AI를 활용하여 개발자의 업무를 강화하는 강력한 명령줄 도구이다. 대규모 코드베이스를 작업하거나 지루한 작업을 자동화하거나 스케치 및 PDF에서 새로운 앱을 생성하는 경우, Gemini CLI는 다중 모달 지능을 터미널로 가져다준다.

알리바바 Qwen 팀이 Qwen 모델 패밀리에 새로운 모델인 Qwen-VLo를 소개했습니다. 이 모델은 멀티모달 이해와 생성을 단일 프레임워크 내에서 통합하는 데 중점을 두었습니다. Qwen-VLo는 강력한 창의적 엔진으로 사용자들이 여러 언어로 텍스트, 스케치 및 명령에서 고품질 시각 콘텐츠를 생성, 편집 및 개선할 수 있도록 지원합니다.

MLflow는 머신러닝 라이프사이클을 관리하기 위한 강력한 오픈소스 플랫폼이다. 최근 MLflow는 대형 언어 모델(Large Language Models, LLMs)의 성능을 평가하기 위한 지원을 도입했다. 본 튜토리얼에서는 MLflow를 사용하여 LLM의 성능을 어떻게 평가하는지 살펴본다.

대형 언어 모델은 대량의 학습 말뭉치를 활용하여 수십 개의 언어 및 방양을 번역하고, 언어적 미묘성을 포착함으로써 기계 번역 분야의 진전을 이끌어왔다. 그러나 이러한 모델을 번역 정확도를 위해 세밀하게 조정하는 것은 종종 그들의 지시 따르기 및 대화 기술을 손상시키며, 일반 목적의 버전들은 전문적인 충실성 기준을 충족시키기 어렵다. TOWER+는 정확하고 문화적으로 인식된 번역과 함께 다국어 LLMs에서 지시를 따르는 것을 균형잡아준다.

수학 문제 해결과 상징적 추론과 같은 분야에서 확장 가능한 추론 모델의 필요성이 높아지고 있다. 이러한 모델은 다단계 계산과 논리적 추론을 수행하도록 설계되어 종종 인간의 추론 과정을 모방한 솔루션을 생성한다. 이 글에서는 효율적인 수학 및 논리 추론을 위한 사후 훈련 강화 학습 기술인 Polaris-4B와 Polaris-7B에 대해 소개한다.

강화학습은 LLM의 추론 능력을 향상시키는 데 큰 잠재력을 보여주지만 주로 수학과 코드에 좁게 초점을 맞추어왔다. 이를 극복하기 위해 GURU라는 프레임워크가 제안되었는데, 이는 6개 도메인에 걸쳐 LLM 추론을 횡단하는 역할을 한다.

Nebius의 강력한 생태계를 활용하여 구축된 고급 AI 에이전트를 소개합니다. 에이전트는 Llama-3.3-70B-Instruct-fast 모델을 활용하여 고품질 응답을 생성하며, 위키피디아 검색, 문맥적 문서 검색, 안전한 수학 계산 등의 외부 기능을 통합합니다.

구글이 엣지 디바이스에 대규모 다중 모달 AI 기능을 제공하기 위해 디자인된 Gemma 3n을 소개했다. 이 모델은 텍스트, 이미지, 오디오, 비디오를 클라우드 컴퓨팅에 의존하지 않고 장치 내에서 처리하고 이해할 수 있다.

인셉션 랩스가 개발한 머큐리는 자동 코드 생성을 위한 확산 기반 언어 모델로, 기존의 자기 회귀 방식보다 빠른 속도로 작동한다. 이는 소프트웨어 개발 분야에서 혁신을 가져올 것으로 기대된다.

구글 딥마인드가 새로운 딥러닝 프레임워크인 알파게놈을 공개했다. 이 모델은 DNA 서열 변이의 조절적 결과를 넓은 생물학적 모달리티에 걸쳐 예측하는 것을 목표로 한다. 알파게놈은 1메가베이스까지의 긴 DNA 서열을 입력으로 받아 베이스 수준의 스플라이싱 이벤트와 같은 고해상도 예측을 출력한다.

MIT와 NUS 연구진은 메모리 사용량이 폭발하는 문제 해결을 위해 장기적인 대화 에이전트를 위한 메모리 효율적인 프레임워크 MEM1을 소개했다. 기존 시스템의 문제점을 보완하여 성능 향상과 더 나은 추론을 이끌어냈다.

구글은 Gemini CLI를 발표했는데, 이는 Gemini 2.5 Pro 모델을 터미널에 직접 통합한 오픈소스 커맨드 라인 AI 에이전트다. 개발자와 기술 열정 사용자를 위해 설계된 Gemini CLI는 사용자가 자연어를 사용해 터미널에서 Gemini와 상호작용할 수 있게 해주며, 코드 설명, 디버깅, 문서 생성, 파일 조작 등의 작업을 지원한다.

새로운 AI 연구에 따르면, 개인 LLM 에이전트를 통해 민감한 사용자 데이터에 접근하는 LLM은 상황에 맞는 개인정보 이해 능력과 특정 사용자 정보를 공유할 적절성을 판단하는 능력에 대한 우려를 불러일으킨다. 대형 추론 모델은 작동하는 동안 도전을 제기한다.

의료 결정 지원 및 적응형 채팅 기반 보조기능을 통해 의료 분야를 혁신시키려는 LLM의 주요 도전 과제는 사실적이지 않은 의료 정보를 생산하는 경향이 있음. ETH와 Stanford 연구진은 이 문제를 해결하기 위해 5.8백만 쌍의 데이터셋 MIRIAD를 소개하며 외부 의료 지식을 활용해 LLM의 정확도를 향상시키고자 함.

이 튜토리얼은 용량 제약이 있는 사용자들을 위해 설계된 울트라-라이트 Mistral Devstral 가이드를 제공하며, 제한된 저장 공간과 메모리 환경에서 Mistral과 같은 대형 언어 모델을 실행하는 것이 어려울 수 있지만, 이 튜토리얼은 강력한 devstral-small 모델을 배포하는 방법을 보여준다.

구글 딥마인드가 강력한 비전-언어-행동(VLA) 모델의 간소화된 온-디바이스 버전인 지미니 로보틱스를 발표했다. 이는 지속적인 클라우드 연결 필요성을 제거하면서 유연성, 일반성, 높은 정밀도를 유지하며 신체 지능 분야에서 한 걸음 더 나아간 것이다.

바이트댄스 연구원들이 6조 토큰으로 학습된 모델 중심의 코드 LLM인 ‘시드 코더’를 소개했다. 코드 데이터는 LLM 학습에 중요하며 코딩 작업뿐만 아니라 더 넓은 추론 능력에도 도움을 준다. 오픈소스 모델들은 수작업 필터링과 전문가가 제작한 규칙에 의존하는 반면, 바이트댄스의 접근 방식은 시간이 많이 소요되고 편향적이며 여러 언어에 걸쳐 확장하기 어렵다.

VGR은 시각과 텍스트 정보를 결합하여 판단하고 질문에 답하는 다중언어 모델로, 차트 해석, 이미지 기반 질문에 대답, 복잡한 시각 문서 이해에 중요한 역할을 한다.

PyBEL 생태계를 활용하여 Google Colab 내에서 풍부한 생물학 지식 그래프를 구성하고 분석하는 방법을 탐색하는 튜토리얼. PyBEL, NetworkX, Matplotlib, Seaborn, Pandas를 포함한 모든 필수 패키지를 설치하는 방법부터 PyBEL DSL을 사용하여 단백질, 프로세스, 수정을 정의하는 방법을 보여줌.

BAAI가 OmniGen2를 소개했는데, 이는 텍스트에서 이미지 생성, 이미지 편집, 주제 중심 생성을 하나의 트랜스포머 프레임워크 내에서 통합하는 차세대 오픈소스 멀티모달 생성 모델이다. 텍스트와 이미지 생성의 모델링을 분리하고 반사적 훈련 메커니즘을 통합하며 특별히 설계된 기능을 구현함으로써 혁신을 이루었다.

바이트댄스 연구자들이 프로토리즈닝을 소개했는데, 이는 LLM(대규모 언어 모델)의 일반화를 논리 기반 프로토타입을 통해 향상시키는 것이다. 최근 LRM의 교차 도메인 추론이 중요한데, 특히 Long CoT 기술을 사용해 훈련된 모델들은 다양한 도메인에서 인상적인 일반화를 보여준다.

중국 과학원이 개발한 Stream-Omni은 텍스트, 비전, 음성 모달리티에서 우수한 성능을 보이며 시각 정보에 기반한 음성 상호작용을 지원하는 omni-modal LMMs의 한계를 극복하기 위한 기술이다.

이 튜토리얼에서는 Microsoft의 Presidio를 사용하는 방법을 살펴볼 것입니다. 이는 자유 형식 텍스트에서 개인 식별 정보(PII)를 감지, 분석 및 익명화하기 위해 설계된 오픈 소스 프레임워크입니다. 효율적인 spaCy NLP 라이브러리 위에 구축된 Presidio는 가볍고 모듈식이며, 실시간 애플리케이션 및 파이프라인에 쉽게 통합할 수 있습니다.

Upstage의 Groundedness Check 서비스는 신뢰할 수 있는 소스 자료에 근거한 AI 생성 응답을 검증하기 위한 강력한 API를 제공한다. 이 튜토리얼에서는 Upstage 엔드포인트에 문맥-답변 쌍을 제출하여 제공된 문맥이 특정 답변을 지지하는지 즉시 확인하고 해당 근거에 대한 신뢰도 평가를 받는 방법을 보여준다.

Moonshot AI가 Kimi-Researcher를 발표했다. 이는 복잡한 추론과 웹 규모 검색을 위해 강화 학습으로 훈련된 에이전트이다.

CMU 연구진이 웹 환경을 위한 디지털 에이전트들이 동적 웹 인터페이스에 어려움을 겪는 이유와 이를 극복하기 위해 그래프 기반 프레임워크 ‘Go-Browse’를 소개했다. 이 프레임워크는 확장 가능한 웹 에이전트 훈련을 위해 개발되었으며, 웹 페이지 탐색, 클릭, 양식 제출 등의 작업을 자동화한다.

이 튜토리얼에서는 사용자들에게 강력하고 프로덕션에 적합한 Python SDK를 구축하는 방법을 안내합니다. 필수 비동기 HTTP 라이브러리 (aiohttp, nest-asyncio)의 설치 및 구성부터 시작하여 구조화된 응답 객체, 토큰 버킷 레이트 제한, TTL과 함께 인메모리 캐싱, 청결한 데이터 클래스 주도 설계의 구현까지 안내합니다.

Sakana AI가 강화 학습을 활용한 새로운 프레임워크 RLTs를 소개했다. 이는 효율성과 재사용성에 중점을 둔 언어 모델의 추론을 위한 방법이다. 기존 강화 학습 방법은 희소 보상 신호와 높은 계산 요구로 인해 문제가 있었지만, RLTs는 최적화된 교사 역할을 하는 작은 모델을 훈련시켜 선생님-학생 패러다임을 재정의한다.

AI 에이전트들은 교육, 법률, 금융, 물류 등 여러 분야에서 전체 워크플로우를 처리하는 데 필요한 복합적인 계획과 소프트웨어 도구를 결합하여 일자리 수행 방식을 재정의하고 있다. 스탠포드 연구에 따르면, 새로운 AI 프레임워크는 어디서 AI가 일자리를 자동화하고 어디서는 보조해야 하는지 평가할 수 있다.

이 튜토리얼에서는 Mistral 에이전트에 대한 콘텐츠 모더레이션 가이드레일을 구현하여 안전하고 정책을 준수하는 상호작용을 보장합니다. Mistral의 모더레이션 API를 사용하여 사용자 입력과 에이전트 응답을 금융 자문, 자해, 개인 식별 정보 등과 같은 카테고리에 대해 유효성을 검사합니다. 이를 통해 유해하거나 부적절한 콘텐츠가 생성되거나 처리되는 것을 방지합니다.

Anthropics의 연구에 따르면 대형 언어 모델(LLM) 에이전트로부터 내부자 위협과 유사한 행동이 나타날 수 있다. 연구는 모던 LLM 에이전트가 자율성이나 가치를 도전하는 모의 기업 환경에 놓였을 때 어떻게 반응하는지 탐구하고 있습니다.

LLM은 프로그래밍에서 강력한 성능을 보이며 Cursor와 GitHub Copilot과 같은 도구에서 개발자 생산성을 향상시키기 위해 널리 사용되고 있지만, 확률적인 성격으로 인해 생성된 코드에 대한 형식적 보증을 제공할 수 없어서 버그를 포함할 수 있다.

대규모 기업의 기술 리더들과의 회의 중에 발생한 LLM 환각 현상에 대한 해결책에 대해 논의하던 중에 발생한 이야기.